The LMAX Disruptor is a high performance inter-thread messaging library. It grew out of LMAX’s research into concurrency, performance and non-blocking algorithms and today forms a core part of their Exchange’s infrastructure.
Using the Disruptor
Introduction
The Disruptor is a library that provides a concurrent ring buffer data structure. It is designed to provide a low-latency, high-throughput work queue in asynchronous event processing architectures.
To understand the benefits of the Disruptor we can compare it to something well understood and quite similar in purpose.
In the case of the Disruptor this would be Java’s BlockingQueue.
Like a queue the purpose of the Disruptor is to move data (e.g. messages or events) between threads within the same process.
However, there are some key features that the Disruptor provides that distinguish it from a queue.
They are:
-
Multicast events to consumers, with consumer dependency graph.
-
Pre-allocate memory for events.
Core Concepts
Before we can understand how the Disruptor works, it is worthwhile defining a number of terms that will be used throughout the documentation and the code. For those with a DDD bent, think of this as the ubiquitous language of the Disruptor domain.
-
Ring Buffer: The Ring Buffer is often considered the main aspect of the Disruptor. However, from 3.0 onwards, the Ring Buffer is only responsible for the storing and updating of the data (
Events) that move through the Disruptor. For some advanced use cases, it can even be completely replaced by the user. -
Sequence: The Disruptor uses
Sequences as a means to identify where a particular component is up to. Each consumer (Event Processor) maintains aSequenceas does the Disruptor itself. The majority of the concurrent code relies on the movement of these Sequence values, hence theSequencesupports many of the current features of anAtomicLong. In fact the only real difference between the two is that theSequencecontains additional functionality to prevent false sharing betweenSequences and other values. -
Sequencer: The Sequencer is the real core of the Disruptor. The two implementations (single producer, multi producer) of this interface implement all the concurrent algorithms for fast, correct passing of data between producers and consumers.
-
Sequence Barrier: The Sequencer produces a Sequence Barrier that contains references to the main published
Sequencefrom the Sequencer and theSequences of any dependent consumer. It contains the logic to determine if there are any events available for the consumer to process. -
Wait Strategy: The Wait Strategy determines how a consumer will wait for events to be placed into the Disruptor by a producer. More details are available in the section about being optionally lock-free.
-
Event: The unit of data passed from producer to consumer. There is no specific code representation of the Event as it defined entirely by the user. -
Event Processor: The main event loop for handling events from the Disruptor and has ownership of consumer’s Sequence. There is a single representation called BatchEventProcessor that contains an efficient implementation of the event loop and will call back onto a user supplied implementation of the EventHandler interface.
-
Event Handler: An interface that is implemented by the user and represents a consumer for the Disruptor.
-
Producer: This is the user code that calls the Disruptor to enqueue
Events. This concept also has no representation in the code.
To put these elements into context, below is an example of how LMAX uses the Disruptor within its high performance core services, e.g. the exchange.
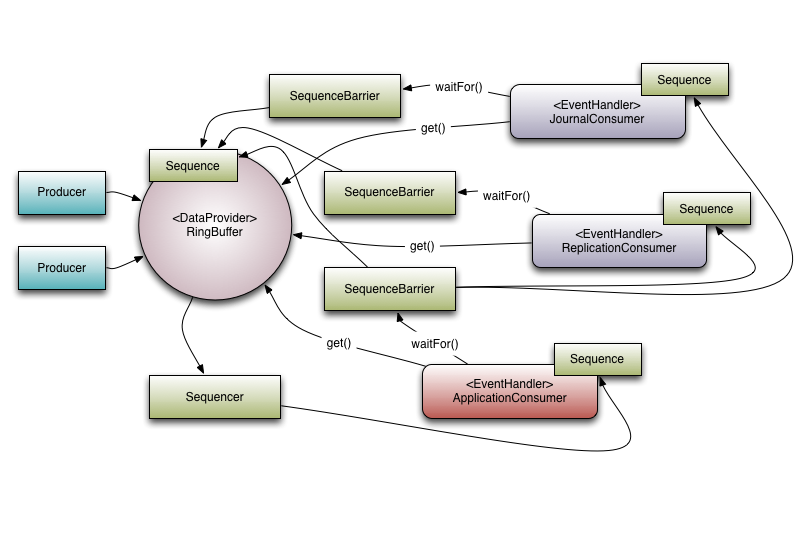
Multicast Events
This is the biggest behavioural difference between queues and the Disruptor.
When you have multiple consumers listening on the same Disruptor, it publishes all events to all consumers. In contrast, a queue will only send a single event to a single consumer. You can use this behaviour of the Disruptor when you need to independent multiple parallel operations on the same data.
Consumer Dependency Graph
To support real world applications of the parallel processing behaviour it was necessary to support co-ordination between the consumers. Referring back to the example described above, it is necessary to prevent the business logic consumer from making progress until the journalling and replication consumers have completed their tasks. We call this concept “gating” (or, more correctly, the feature is a form of “gating”).
“Gating” happens in two places:
-
Firstly we need to ensure that the producers do not overrun consumers. This is handled by adding the relevant consumers to the Disruptor by calling
RingBuffer.addGatingConsumers(). -
Secondly, the case referred to previously is implemented by constructing a SequenceBarrier containing Sequences from the components that must complete their processing first.
Referring to Figure 1 there are 3 consumers listening for Events from the Ring Buffer. There is a dependency graph in this example.
The ApplicationConsumer depends on the JournalConsumer and ReplicationConsumer.
This means that the JournalConsumer and ReplicationConsumer can run freely in parallel with each other.
The dependency relationship can be seen by the connection from the ApplicationConsumer's SequenceBarrier to the Sequences of the JournalConsumer and ReplicationConsumer.
It is also worth noting the relationship that the Sequencer has with the downstream consumers.
One of its roles is to ensure that publication does not wrap the Ring Buffer.
To do this none of the downstream consumer may have a Sequence that is lower than the Ring Buffer’s Sequence less the size of the Ring Buffer.
However, by using the graph of dependencies an interesting optimisation can be made.
Because the ApplicationConsumer's Sequence is guaranteed to be less than or equal to that of the JournalConsumer and ReplicationConsumer (that is what that dependency relationship ensures) the Sequencer need only look at the Sequence of the ApplicationConsumer.
In a more general sense the Sequencer only needs to be aware of the Sequences of the consumers that are the leaf nodes in the dependency tree.
Event Pre-allocation
One of the goals of the Disruptor is to enable use within a low latency environment. Within low-latency systems it is necessary to reduce or remove memory allocations. In Java-based system the purpose is to reduce the number stalls due to garbage collection [1].
To support this the user is able to preallocate the storage required for the events within the Disruptor.
During construction and EventFactory is supplied by the user and will be called for each entry in the Disruptor’s Ring Buffer.
When publishing new data to the Disruptor the API will allow the user to get hold of the constructed object so that they can call methods or update fields on that store object.
The Disruptor provides guarantees that these operations will be concurrency-safe as long as they are implemented correctly.
Optionally Lock-free
Another key implementation detail pushed by the desire for low-latency is the extensive use of lock-free algorithms to implement the Disruptor. All memory visibility and correctness guarantees are implemented using memory barriers and/or compare-and-swap operations.
|
There is only one use-case where an actual lock is required and that is within the This is done solely for the purpose of using a condition so that a consuming thread can be parked while waiting for new events to arrive. Many low-latency systems will use a busy-wait to avoid the jitter that can be incurred by using a condition; however, in number of system busy-wait operations can lead to significant degradation in performance, especially where the CPU resources are heavily constrained, e.g. web servers in virtualised-environments. |
Getting Started
Getting the Disruptor
The Disruptor jar file is available from Maven Central and can be integrated into your dependency manager of choice from there.
Basic Produce and Consume
To get started with the Disruptor we are going to consider very simple and contrived example.
We will pass a single long value from a producer to a consumer, and the consumer will simply print out the value.
There are currently several styles of writing publishers and consumers for the Disruptor. Whilst they are all fundamentally similar, there may be slight nuances in each approach that will be covered below.
Firstly we will define the Event that will carry the data and is common to all following examples:
LongEventpublic class LongEvent
{
private long value;
public void set(long value)
{
this.value = value;
}
@Override
public String toString()
{
return "LongEvent{" + "value=" + value + '}';
}
}In order to allow the Disruptor to preallocate these events for us, we need to an EventFactory that will perform the construction.
This could be a method reference, such as LongEvent::new or an explicit implementation of the EventFactory interface:
LongEventFactorypublic class LongEventFactory implements EventFactory<LongEvent>
{
@Override
public LongEvent newInstance()
{
return new LongEvent();
}
}Once we have the event defined, we need to create a consumer that will handle these events.
As an example, we will create an EventHandler that will print the value out to the console.
LongEventHandlerpublic class LongEventHandler implements EventHandler<LongEvent>
{
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("Event: " + event);
}
}Finally, we will need a source for these events.
For simplicity, we will assume that the data is coming from some sort of I/O device, e.g. network or file in the form of a ByteBuffer.
Publishing
Using Lambdas
Since version 3.0 of the Disruptor it has been possible to use a Lambda-style API to write publishers. This is the preferred approach, as it encapsulates much of the complexity of the alternatives.
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void main(String[] args) throws Exception
{
int bufferSize = 1024; (1)
Disruptor<LongEvent> disruptor = (2)
new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);
disruptor.handleEventsWith((event, sequence, endOfBatch) ->
System.out.println("Event: " + event)); (3)
disruptor.start(); (4)
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); (5)
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);
Thread.sleep(1000);
}
}
}| 1 | Specify the size of the ring buffer, must be power of 2. |
| 2 | Construct the Disruptor |
| 3 | Connect the handler |
| 4 | Start the Disruptor, starts all threads running |
| 5 | Get the ring buffer from the Disruptor to be used for publishing. |
|
Notice that the lambda used for If we were to instead write that code as: Example of a capturing lambda
This would create a capturing lambda, meaning that it would need to instantiate an object to hold the |
Given that method references can be used instead of anonymous lambdas, it is possible to rewrite the example in this fashion:
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void handleEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println(event);
}
public static void translate(LongEvent event, long sequence, ByteBuffer buffer)
{
event.set(buffer.getLong(0));
}
public static void main(String[] args) throws Exception
{
int bufferSize = 1024;
Disruptor<LongEvent> disruptor =
new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);
disruptor.handleEventsWith(LongEventMain::handleEvent);
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent(LongEventMain::translate, bb);
Thread.sleep(1000);
}
}
}Using Translators
Prior to version 3.0, the preferred way of publishing messages was via the Event Publisher/Event Translator interfaces:
LongEventProducerimport com.lmax.disruptor.EventTranslatorOneArg;
import com.lmax.disruptor.RingBuffer;
import java.nio.ByteBuffer;
public class LongEventProducer
{
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer)
{
this.ringBuffer = ringBuffer;
}
private static final EventTranslatorOneArg<LongEvent, ByteBuffer> TRANSLATOR =
new EventTranslatorOneArg<LongEvent, ByteBuffer>()
{
@Override
public void translateTo(LongEvent event, long sequence, ByteBuffer bb)
{
event.set(bb.getLong(0));
}
};
public void onData(ByteBuffer bb)
{
ringBuffer.publishEvent(TRANSLATOR, bb);
}
}This approach uses number of extra classes (e.g. handler, translator) that are not explicitly required when using lambdas. The advantage of here is that the translator code can be pulled into a separate class and easily unit tested.
The Disruptor provides a number of different interfaces (EventTranslator, EventTranslatorOneArg, EventTranslatorTwoArg, etc.) that can be implemented to provide translators.
This is to allow for the translators to be represented as static classes and lambdas (see above).
The arguments to the translation method are passed through the call on the Ring Buffer through to the translator.
Publishing Using the Legacy API
There is a more "raw" approach that we can use:
LongEventProducerimport com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.examples.longevent.LongEvent;
import java.nio.ByteBuffer;
public class LongEventProducer
{
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer)
{
this.ringBuffer = ringBuffer;
}
public void onData(ByteBuffer bb)
{
long sequence = ringBuffer.next(); (1)
try
{
LongEvent event = ringBuffer.get(sequence); (2)
event.set(bb.getLong(0)); (3)
}
finally
{
ringBuffer.publish(sequence);
}
}
}| 1 | Grab the next sequence |
| 2 | Get the entry in the Disruptor for that sequence |
| 3 | Fill the entry with data |
What becomes immediately obvious is that event publication becomes more involved than using a simple queue. This is due to the desire for Event pre-allocation. It requires (at the lowest level) a 2-phase approach to message publication, i.e. claim the slot in the ring buffer and then publish the available data.
|
It is also necessary to wrap publication in a If we claim a slot in the Ring Buffer (calling Specifically, in the multi-producer case, this will result in the consumers stalling and being unable to recover without a restart.
Therefore, it is recommended that either the lambda or |
The final step is to wire the whole thing together. Whilst it is possible to wire up each component manually, this can be complicated and so a DSL is provided to simplify construction.
| Some of the more complicated options are not available via the DSL; however, it is suitable for most circumstances. |
LongEventProducerimport com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.examples.longevent.LongEventFactory;
import com.lmax.disruptor.examples.longevent.LongEventHandler;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void main(String[] args) throws Exception
{
LongEventFactory factory = new LongEventFactory();
int bufferSize = 1024;
Disruptor<LongEvent> disruptor =
new Disruptor<>(factory, bufferSize, DaemonThreadFactory.INSTANCE);
disruptor.handleEventsWith(new LongEventHandler());
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
producer.onData(bb);
Thread.sleep(1000);
}
}
}Basic Tuning Options
Using the above approach will work functionally in the widest set of deployment scenarios. However, there are a number of tuning options that can be used to improve performance.
The two main options for tuning are:
Both of these options are set when constructing a Disruptor:
public class LongEventMain
{
public static void main(final String[] args)
{
//.....
Disruptor<LongEvent> disruptor = new Disruptor(
factory,
bufferSize,
DaemonThreadFactory.INSTANCE,
ProducerType.SINGLE, (1)
new BlockingWaitStrategy() (2)
);
//.....
}
}| 1 | Use ProducerType#SINGLE to create a SingleProducerSequencer; use ProducerType#MULTI to create a MultiProducerSequence |
| 2 | Set the desired WaitStrategy |
Single vs. Multiple Producers
One of the best ways to improve performance in concurrent systems is to adhere to the Single Writer Principle, this applies to the Disruptor. If you are in the situation where there will only ever be a single thread producing events into the Disruptor, then you can take advantage of this to gain additional performance.
To give an indication of how much of a performance advantage can be achieved through this technique we can change the producer type in the OneToOne performance test. Tests run on i7 Sandy Bridge MacBook Air.
Run 0 |
Disruptor=26,553,372 ops/sec |
Run 1 |
Disruptor=28,727,377 ops/sec |
Run 2 |
Disruptor=29,806,259 ops/sec |
Run 3 |
Disruptor=29,717,682 ops/sec |
Run 4 |
Disruptor=28,818,443 ops/sec |
Run 5 |
Disruptor=29,103,608 ops/sec |
Run 6 |
Disruptor=29,239,766 ops/sec |
Run 0 |
Disruptor=89,365,504 ops/sec |
Run 1 |
Disruptor=77,579,519 ops/sec |
Run 2 |
Disruptor=78,678,206 ops/sec |
Run 3 |
Disruptor=80,840,743 ops/sec |
Run 4 |
Disruptor=81,037,277 ops/sec |
Run 5 |
Disruptor=81,168,831 ops/sec |
Run 6 |
Disruptor=81,699,346 ops/sec |
Alternative Wait Strategies
The default WaitStrategy used by the Disruptor is the BlockingWaitStrategy.
Internally the BlockingWaitStrategy uses a typical lock and condition variable to handle thread wake-up.
The BlockingWaitStrategy is the slowest of the available wait strategies, but is the most conservative with the respect to CPU usage and will give the most consistent behaviour across the widest variety of deployment options.
Knowledge of the deployed system can allow for additional performance by choosing a more appropriate wait strategy:
-
SleepingWaitStrategy →
Like the BlockingWaitStrategy the SleepingWaitStrategy it attempts to be conservative with CPU usage by using a simple busy wait loop.
The difference is that the SleepingWaitStrategy uses a call to LockSupport.parkNanos(1) in the middle of the loop.
On a typical Linux system this will pause the thread for around 60µs.
This has the benefits that the producing thread does not need to take any action other increment the appropriate counter and that it does not require the cost of signalling a condition variable. However, the mean latency of moving the event between the producer and consumer threads will be higher.
It works best in situations where low latency is not required, but a low impact on the producing thread is desired. A common use case is for asynchronous logging.
-
YieldingWaitStrategy →
The YieldingWaitStrategy is one of two WaitStrategys that can be use in low-latency systems.
It is designed for cases where there is the option to burn CPU cycles with the goal of improving latency.
The YieldingWaitStrategy will busy spin, waiting for the sequence to increment to the appropriate value.
Inside the body of the loop Thread#yield() will be called allowing other queued threads to run.
This is the recommended wait strategy when you need very high performance, and the number of EventHandler threads is lower than the total number of logical cores, e.g. you have hyper-threading enabled.
-
BusySpinWaitStrategy →
The BusySpinWaitStrategy is the highest performing WaitStrategy.
Like the YieldingWaitStrategy, it can be used in low-latency systems, but puts the highest constraints on the deployment environment.
This wait strategy should only be used if the number of EventHandler threads is lower than the number of physical cores on the box, e.g. hyper-threading should be disabled.
Clearing Objects From the Ring Buffer
When passing data via the Disruptor, it is possible for objects to live longer than intended. To avoid this happening it may be necessary to clear out the event after processing it.
If you have a single event handler, clearing out the value within the same handler is sufficient. If you have a chain of event handlers, then you may need a specific handler placed at the end of the chain to handle clearing out the object.
ObjectEventclass ObjectEvent<T>
{
T val;
void clear()
{
val = null;
}
}ClearingEventHandlerimport com.lmax.disruptor.EventHandler;
public class ClearingEventHandler<T> implements EventHandler<ObjectEvent<T>>
{
@Override
public void onEvent(ObjectEvent<T> event, long sequence, boolean endOfBatch)
{
event.clear(); (1)
}
}| 1 | Failing to call clear() here will result in the object associated with the event to live until it is overwritten.
This will only happen once the ring buffer has wrapped around to the beginning. |
ClearingEventHandler public static void main(String[] args)
{
Disruptor<ObjectEvent<String>> disruptor = new Disruptor<>(
() -> new ObjectEvent<>(), BUFFER_SIZE, DaemonThreadFactory.INSTANCE);
disruptor
.handleEventsWith(new ProcessingEventHandler())
.then(new ClearingEventHandler());
}Advanced Techniques
Dealing With Large Batches
public class EarlyReleaseHandler implements EventHandler<LongEvent>
{
private Sequence sequenceCallback;
private int batchRemaining = 20;
@Override
public void setSequenceCallback(final Sequence sequenceCallback)
{
this.sequenceCallback = sequenceCallback;
}
@Override
public void onEvent(final LongEvent event, final long sequence, final boolean endOfBatch)
{
processEvent(event);
boolean logicalChunkOfWorkComplete = isLogicalChunkOfWorkComplete();
if (logicalChunkOfWorkComplete)
{
sequenceCallback.set(sequence);
}
batchRemaining = logicalChunkOfWorkComplete || endOfBatch ? 20 : batchRemaining;
}
private boolean isLogicalChunkOfWorkComplete()
{
// Ret true or false based on whatever criteria is required for the smaller
// chunk. If this is doing I/O, it may be after flushing/syncing to disk
// or at the end of DB batch+commit.
// Or it could simply be working off a smaller batch size.
return --batchRemaining == -1;
}
private void processEvent(final LongEvent event)
{
// Do processing
}
}Design and Implementation
-
Single Producer Algorithm
-
Multiple Producer Algorithm
Known Issues
-
On 32 bit Linux systems it appears that
LockSupport.parkNanos()is quite expensive, therefore using theSleepingWaitStrategyis not recommended.
Batch Rewind
The Feature
When using the BatchEventProcessor to handle events as batches, there is a feature available that can be used to recover from an exception named "Batch Rewind".
If something goes wrong while handling an event that is recoverable, the user can throw a RewindableException. This will invoke the BatchRewindStrategy instead of the usual ExceptionHandler to decide whether the sequence number should rewind back to the beginning of the batch to be reattempted or rethrow and delegate to the ExceptionHandler.
e.g.
When using the SimpleBatchRewindStrategy (which will always rewind) then the BatchEventProcessor receives a batch from 150 → 155, but a temporary failure happens on sequence 153 (which throws a RewindableException). The events processed will look like the following…
150, 151, 152, 153(failed -> rewind), 150, 151, 152, 153(succeeded this time), 154, 155The default BatchRewindStrategy is the SimpleBatchRewindStrategy but different strategies can be provided to the BatchEventProcessor like so…
batchEventProcessor.setRewindStrategy(batchRewindStrategy);Use Case
This can be very useful when batches are handled as database transactions. So the start of a batch starts a transaction, events are handled as statements, and only committed at the end of a batch.
Happy case
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> insert a row;
Event 3 -> insert a row;
Batch end -> COMMIT;Sad case without Batch Rewind
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> DATABASE has a blip and can not commit
Throw error -> ROLLBACK;
User needs to explcitily reattempt the batch or choose to abandon the batchSad case with Batch Rewind
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> DATABASE has a blip and can not insert
Throw RewindableException -> ROLLBACK;
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> insert a row;
Event 3 -> insert a row;
Batch end -> COMMIT;