Read This First
To understand the problem the Disruptor is trying to solve, and to get a feel for why this concurrency framework is so fast, read the Technical Paper. It also contains detailed performance results.
And now for some words from our sponsors…
LMAX are recruiting once again. If you are interested in working with a great team, with some amazing technology, and think you can add something to the mix then please check out our jobs page.
What is the Disruptor?
LMAX aims to be the fastest trading platform in the world. Clearly, in order to achieve this we needed to do something special to achieve very low-latency and high-throughput with our Java platform. Performance testing showed that using queues to pass data between stages of the system was introducing latency, so we focused on optimising this area.
The Disruptor is the result of our research and testing. We found that cache misses at the CPU-level, and locks requiring kernel arbitration are both extremely costly, so we created a framework which has "mechanical sympathy" for the hardware it’s running on, and that’s lock-free.
This is not a specialist solution, it’s not designed to work only for a financial application. The Disruptor is a general-purpose mechanism for solving a difficult problem in concurrent programming.
It works in a different way to more conventional approaches, so you use it a little differently than you might be used to. For example, applying the pattern to your system is not as simple as replacing all your queues with the magic ring buffer. We’ve got:
-
a User Guide to guide you,
-
a growing number of blogs and articles giving an overview of how it works,
-
the technical paper goes into some detail as you’d expect,
-
and the performance tests give examples of how to use the Disruptor.
If you prefer real, live people explaining things instead of a dry paper or content-heavy website, there’s always the presentation Mike and Martin gave at QCon San Francisco. If you fancy a natter with the folks involved head over to our Discussion Group. Martin Thompson will also witter on occasionally about performance in his Mechanical Sympathy blog. Martin Fowler has also done a great review of the Disruptor’s application at LMAX.
What’s the big deal?
It’s fast. Very fast.
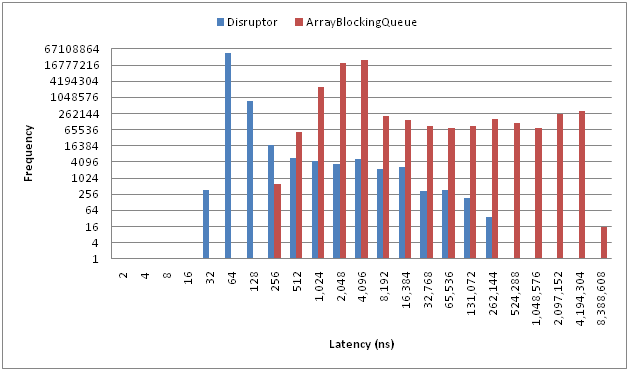
Note that this is a log-log scale, not linear. If we tried to plot the comparisons on a linear scale, we’d run out of space very quickly. We have performance results of the test that produced these results, plus others of throughput testing.
Great What do I do next?
-
Read the User Guide,
-
Read the API documentation,
-
Check out our Frequently Asked Questions
-
Want to work on the Disruptor? Read the Developer Guide,
Discussion, Blogs & Other Useful Links
-
Mechanical Sympathy (Martin Thompson)
-
Bad Concurrency (Michael Barker)
Changelog
The changelog can be found here.